Technical Scoping: How Shipping API Dojo v2 Designed Its Content-Family Foundation

Technical Scoping: The Decisions Before the Code
Before writing a single line of implementation code for Shipping API Dojo v2, I needed a complete technical blueprint.
Issue #7 was that scoping phase. No implementation—just decisions. Data models, randomization strategy, auth/billing/email/domain architecture, and the handoff checklist that would make the actual build possible.
These are the decisions I made and the reasoning behind them.
The content-family data model
The first question was how to structure content for a system that needs both stability and variety in a way that produces very high credibility.
v1 had monolithic lesson files. That worked for reference, but it didn't work for randomized practice. If every drill is a unique file, shuffling them means breaking every reference.
The content-family model solves that:
- Lessons, drill families, and scenario families have stable IDs
- Each family can have multiple run variants
- Progress maps to family IDs, not specific runs
- The model is future-compatible with TanStack AI content generation
This is a structural shift. Instead of 100 unique drill files, I might have 20 drill families with 5 variants each. The family ID stays constant. The variant changes based on a seed.
That's what makes progress tracking stable. If I complete drill-family-abc, that completion survives even if the specific run I saw was variant-3 and you saw variant-5.
The data model also includes inline lesson sections, run types, and clear ownership boundaries for auth, billing, email, entitlements, and SEO-critical route behavior. Every piece of the system needs a defined home before implementation starts.
Seeded randomization and SSR boundaries
Randomization is the core feature of v2, but it can't break SEO.
The constraint is clear: lessons, wiki pages, and directory surfaces must stay crawlable and SSR-visible. The domain cutover to shipping.apidojo.app needs to be a controlled site move, not an ad hoc rename.
That means randomization has to be surgical:
- Primary lesson content stays SSR-visible
- Only the parts that truly need runtime seeds randomize
- MCQ answer order, drill sequence, and scenario order are the randomized elements
- ClientOnly is justified only where SSR preservation would break the feature
The seeded randomization strategy is deterministic. Same seed, same order. Different seed, different order. That's what makes testing possible and progress tracking reliable.
I also defined SSR-preserving execution boundaries. Some things must happen on the server. Some things can happen on the client. The line between them is explicit, not accidental.
Auth, progress, and the server-authoritative model
v2 is the moment Shipping API Dojo becomes a real product with real users. That means real authentication and real progress tracking.
The decisions here:
- Better Auth for user accounts, sessions, and organization management
- Neon Postgres with Drizzle ORM for server-authoritative progress tracking
- Progress migration from v1's local storage to server-side storage
- Better Auth's organization model mapped to tenants for future multi-product support
The key principle is server-authoritative data. Progress now lives on the server, not in the browser. That means authenticated server functions for signed-in progress and server-only HTTP request handlers for webhook endpoints that require raw-body signature verification.
This also means the platform-neutral constraint: content, scoring, progress, entitlement, and certificate logic must remain platform-neutral so a future native client can reuse the same backend and domain model without re-architecture.
Entitlements, billing, and Creem
Shipping API Dojo v2 introduces a freemium model with a flat-fee Pro tier and optional annual billing. Paid plans come with a three-day grace period before activation.
The billing stack:
- Creem as the merchant of record, replacing earlier Polar assumptions
- Better Auth organization model for tenant management
- Entitlements tied to organization/tenant, not individual users
- Open-core licensing with AGPL-3.0-only for the public repo
- Trademarks and premium materials stay outside the public repo
Creem handles invoicing, tax, payments, refunds, and chargebacks. That's the MoR (merchant of record) model—Creem owns the billing complexity, I own the product logic.
The pricing model follows the per-seat approach defined in scoping: free (1), pro (1), team (2-7 discounted), enterprise (custom). Team and Enterprise plans will not be available at launch. Modules are add-on subscriptions. Currency is currently EUR only.
Email and domain strategy
Transactional email needs a dedicated setup. The decisions:
- apidojo.app is the umbrella/root domain
- shipping.apidojo.app is the production hostname
- Dedicated Resend account and domain for transactional email
- Resend Free allows one verified domain per team with multiple sender identities
The domain cutover is planned as a controlled site move, not an ad hoc rename. That means proper redirects, proper canonical URLs, and proper SEO preservation throughout the transition. Considerations were taken to cover adding multiple future new mirror products with their own subdomain, while remaining under the "API Dojo" umbrella.
The implementation handoff checklist
Scoping is useless if implementation can't actually start. The final deliverable was a handoff checklist:
- Accounts: Better Auth setup, organization/tenant structure
- External services: Neon Postgres, Creem, Resend configuration
- Environment variables: complete list with descriptions
- Launch-readiness prerequisites: DNS, SSL, monitoring, logging
Every scoping area was validated against the current codebase and provider constraints before the auth foundation implementation started. No assumptions about what a provider "should" support—only what it actually supports.
Why scoping mattered
This scoping phase took time. It also saved time.
By the time issue #11 (auth foundation) started, the data model was decision-complete. The randomization strategy was defined. The billing stack was chosen. The domain strategy was clear.
That meant implementation could focus on execution, not discovery. The questions that would have blocked development mid-stream were already answered.
The scoping also made the work resumable. If implementation pauses, the blueprint is still there. The decisions are still documented. The handoff checklist is still valid.
What this enabled
This scoping phase is what made the proof of concept in issue #8 possible. It's what made the full content migration in issue #9 tractable. It's what made the browser smoke suite in issue #17 necessary but manageable.
The technical foundation for Shipping API Dojo v2 wasn't built by accident. It was designed first, externally validated using multiple AI models second, and then implemented third.
This to me is a clear development structure for 2026, regardless of how many people or AI agents are involved in the development.
Related Posts
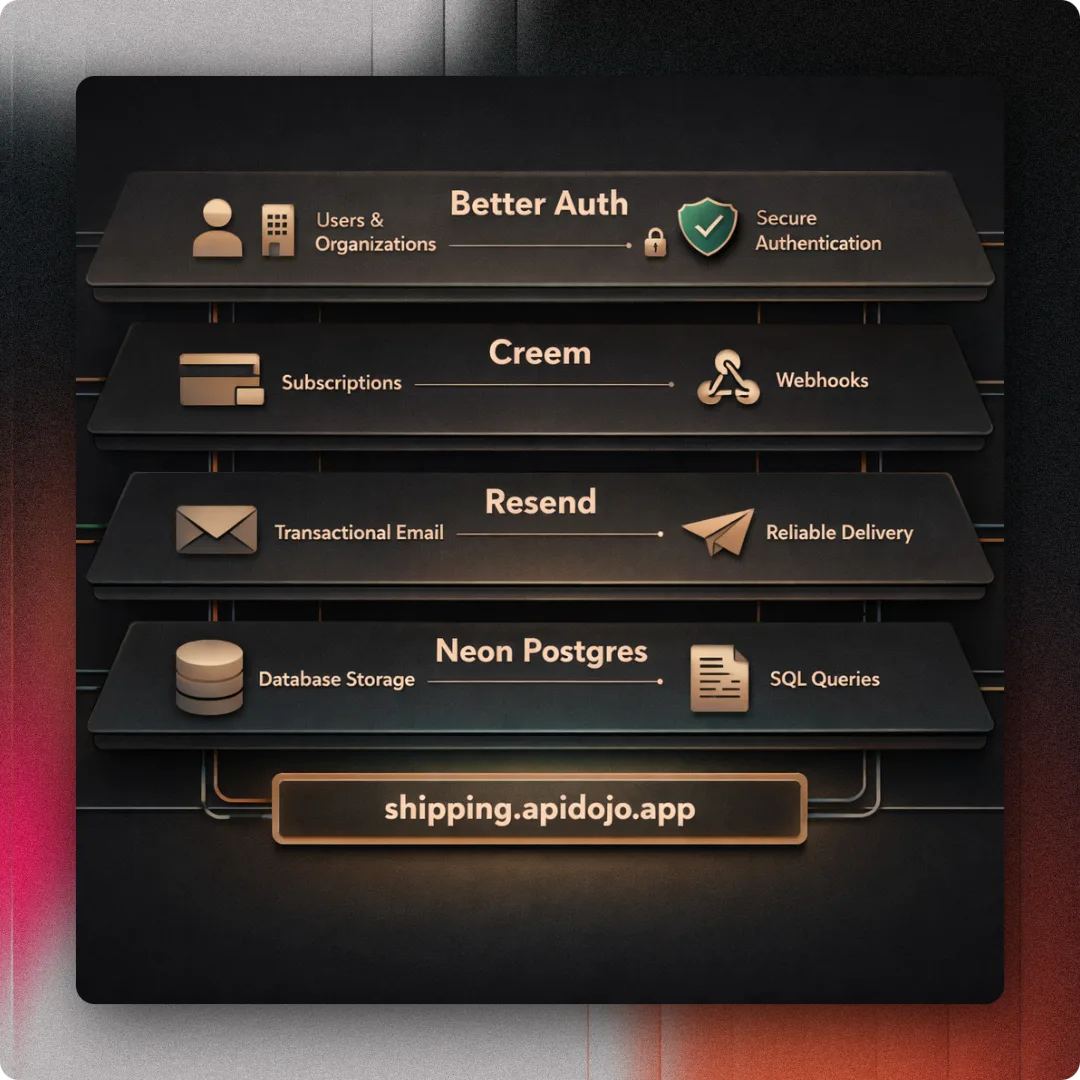
Auth Foundation: Building Better Auth, Creem Billing, and Email Infrastructure for Shipping API Dojo v2
Issue #11 completed the auth, entitlements, billing, email, and domain foundation for Shipping API Dojo v2. Better Auth, Creem, Resend, and the shipping.apidojo.app domain came together.

Browser Smoke Suite: Cost-Efficient Route Validation for Shipping API Dojo v2
Issue #17 added a minimal Playwright smoke suite to complement unit/integration coverage. I built a cost-efficient browser test layer for checkpoint validation and future mirror sites.

Proof of Concept: Validating Seeded Randomization and Content Families in Shipping API Dojo v2
Issue #8 implemented a proof of concept for minimum viable randomization and content families. I validated MCQ shuffling, lesson drill ordering, scenario sequencing, and SSR-safe behavior under TanStack Start.